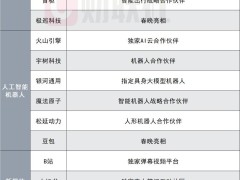
春节前夕,阿里再次在AI领域投下一枚重磅炸弹——新一代开源大模型Qwen3.5正式发布。这款被业界称为"反直觉"的模型,以3970亿参数的"瘦身"姿态,实现了对万亿参数前代旗舰Qwen3-Max的性能超越,更在效率与成本维度展现出颠覆性优势。
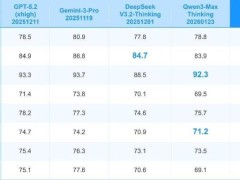
在开源社区,Qwen系列早已成为技术风向标。从Qwen1.5首创细粒度专家模式,到Qwen3摒弃沿用三代的共享专家架构转用路由专家,再到此次Qwen3.5引入混合注意力机制实现"有详有略"的信息处理,这个中国团队始终在自我革新中推动行业进步。最新发布的Qwen3.5-Plus尤为引人注目:其激活参数仅170亿,相当于用5%的算力资源调动满血智能,最终交付的token成本仅为Gemini 3 Pro的1/18。
技术突破的背后是扎实的学术支撑。推动Qwen3.5实现质变的门控技术,源自阿里团队在2025 NeurIPS顶会上斩获最佳论文的成果。这项被业界评价为"重新定义模型效率"的技术,现已完全开源,任何科技公司均可直接吸收应用。这种开放姿态,让中国开源模型阵营形成独特优势——Qwen、GLM、Kimi、DeepSeek等模型构成的多维度技术矩阵,正在对闭源模型形成全面包围之势。
全模态能力的突破成为另一大亮点。Qwen3.5从预训练阶段就采用文本与视觉混合数据联合学习,使视觉与语言在统一参数空间深度融合。这种技术路径与Gemini 3 Pro等国际顶尖模型异曲同工,但中国团队展现出更快的迭代速度。有开发者实测显示,当前国产大模型与全球SOTA的差距已从6个月缩短至3个月,某些细分领域甚至实现反超。
阿里在AI领域的战略布局正显现出独特价值。作为全球少数同时具备芯片、云计算、大模型和应用开发能力的科技公司,其技术栈的完整性曾被比作"中国版谷歌"。随着Qwen3.5在多模态领域的突破,这种对比正在从业务架构层面延伸至技术实力维度。当行业还在讨论"追赶"时,中国团队已用持续的技术爆发改写着游戏规则。
在这个辞旧迎新的时刻,开源社区的开发者们正用代码庆祝这场技术盛宴。有人戏称:"阿里选择在除夕前发新模型,这是要给全球AI圈送'技术年夜饭'。"而更多人开始期待:当开源模型摘下"无定语SOTA"桂冠时,是否会成为改变行业格局的关键转折点?